Research Paper: Quantifying the Uncertainty in Aggregate Queries Over Integrated Datasets
Research Paper Publication2020 - 2023
Data integration is a notoriously difficult and heuristic-driven pro- cess, especially when ground-truth data are not readily available. This paper presents a measure of uncertainty in two-table, one-to- many data integration workflows. Users can use these query results to guide a search through different matching parameters, similar- ity metrics, and constraints. Even though there are exponentially many such matchings, we show that in appropriately constrained circumstances that this result range can be calculated in polynomial time with the Blossom algorithm, a generalization of the Hungarian Algorithm used in Bipartite Graph Matching. We evaluate this on 3 real-world datasets and synthetic datasets, and find that uncertainty estimates are more robust when a graph-matching based approach is used for data integration.
See the Research Paper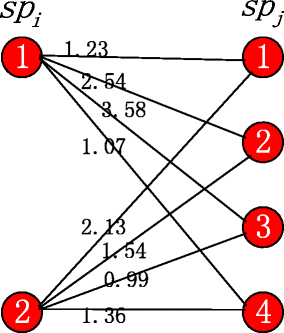
Modeling Opinions & Gender Employment Gap in U.S.
Machine Learning ProjectWinter 2020
Building on the existing literature, this paper studies both conventional drivers of (female) labor force participation and proposed non-conventional drivers of female labor force partic- ipation inspired by the social sciences (e.g., opinions on feminism, abortion.) By including a wide set of features in our data and applying, tuning, and refining a variety of machine learning techniques, we hope to capture more of the complexity behind women’s choice to participate in the labor market. In particular, this research paper aims to: (1) evaluate which data features are relevant in modeling labor force participation and the labor force participa- tion gap (using techniques such as LASSO); (2) evaluate which classes of machine learning techniques have strong predictive power in this setting.
See the Project
Kafka Tooling
Apache KafkaJuly 2019
Apache Kafka is an open-source stream-processing software platform that Braintree uses to stream transaction information in real time. As part of my internship at Braintree, I focused on building tools that could make interacting with Kafka much easier for the platform teams and decrease the load on the Kafka brokers for better performance. I designed and implemented a notification system infrastructure to alert all downstream dependents when a Kafka topic is misbehaving in a
production environment using Capistrano task deployment system. I've also set up a new cloud-based infrastructure to decrease load on Kafka brokers by 43% and keep Kafka tooling separate for other teams’ usage
cools you down.
Please reach out to me via e-mail to see the project

Predicting Yelp Elite Status
Big DataMay 2019
Yelp Elite Status is a nomination based status that some Yelp members can qualify for. However, the Yelp community seems eluded on what the requierements are to be an elite member. In order to answer this question, my team and I developed a logistic regression model using some hypothesized factors by the Yelp community. In addition to it, we used natural language processing via the Flesch Reading Ease algorithm, which helped to see if elevated language in reviews contributed to the Elite status.
Please reach out to me via e-mail to see the project
Spellcheck Tool
CMSC 22200 Software EngineeringSpring 2018
Redis is an in-memory data structure project implementing a distributed, in-memory key-value database with optional durability that supports different kinds of abstract data structures. A Trie data structure did not exist in Redis before, so it was an interesting challenge tom implement a Trie data structure in C for Redis. We then extended this trie data structure to use in a spellcheck tool that we wrote to work in Redis. Using the trie data structure, we achieved to spellcheck in O(n) time complexity.
See the ProjectTwitter Sentiment Analysis
Personal ProjectWinter 2018
This sentiment analysis project that I worked on to prepare for my Girls Who Code internship improved my Natural Language Processing skills and developed my sense of how to use scalable algorithms for big data. I mainly used a mapreduce algorithm to digest large amounts of information.
Please reach out to me via e-mail to see the project and check out my github to see some part of the published project